


- O que é Robots.txt?
- Estrutura
- Aqui estão alguns comandos clássicos e importantes do arquivo robots.txt:
- Mapa do site e robots.txt
- Gerador de arquivo Robots.txt
- Todas as explicações online
- Observe também esta indicação muito recente encontrada na Internet:
O que é Robots.txt?
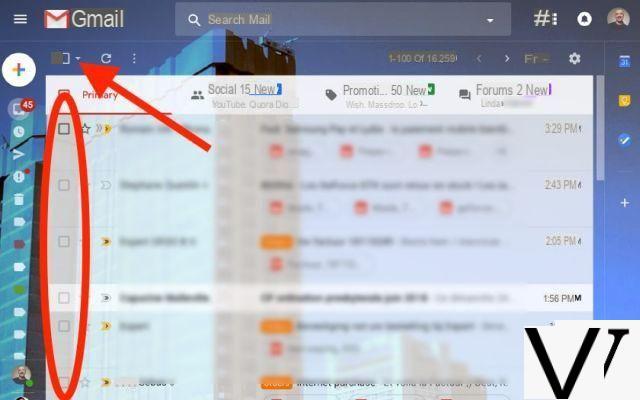
Em seu site, você tenta, tanto quanto possível, garantir que suas páginas sejam indexadas da melhor forma possível por spiders de mecanismos de pesquisa. Mas também pode acontecer que algumas das suas páginas sejam confidenciais (ou em construção) ou de qualquer forma que o seu objetivo não seja distribuí-las amplamente nestes motores. Um site ou uma página em construção, por exemplo, não precisa ser alvo de tal aspiração. É então necessário evitar que certas aranhas os levem em consideração.
Isso pode ser feito usando um arquivo de texto, chamado robots.txt, presente na sua hospedagem, na raiz do seu site. Este arquivo dará indicações para o mecanismo de aranha que vai querer rastrear o seu site, sobre o que ele pode ou não fazer no site. Assim que o spider de um motor chega a um site (por exemplo https://monsite.info/), ele vai procurar o documento presente no endereço https://www.monsite.info/robots.txt antes de ' realizar a menor "aspiração de documento". Se este arquivo existir, ele o lê e segue as indicações fornecidas. Se não o encontrar, inicia o seu trabalho de leitura e registo da página que veio visitar, bem como das que a ela possam estar associadas, visto que nada lhe é proibido.
Estrutura
Deve haver apenas um arquivo robots.txt em um site e deve estar no nível da raiz do site. O nome do arquivo (robots.txt) deve ser sempre criado em letras minúsculas. A estrutura de um arquivo robots.txt é a seguinte:
User-agent: *
Não permitir: / cgi-bin /
Disallow: / time /
Disallow: / lost /
Disallow: / entravaux /
Disallow: /abonnes/prix.html
Neste exemplo:
- User-agent: * significa que o acesso é concedido a todos os agentes (todos os spiders), sejam eles quem forem.
- O robô não explorará os diretórios / cgi-bin /, / tempo /, / perso / e / entravaux / do servidor nem o arquivo / subscribers / prix.html.
O diretório / temp /, por exemplo, corresponde ao endereço https://mysite.info/ Cada diretório a ser excluído da aspiração spider deve ter uma linha Disallow: específica. O comando Disallow: é usado para indicar que "tudo que começa com" a expressão especificada não deve ser indexada.
Então:
Disallow: / perso não permitirá a indexação de https://monsite.info/ ou https://monsite.info/
Disallow: / perso / não indexará https://monsite.info/, mas não se aplicará ao endereço https://monsite.info/
Por outro lado, o arquivo robots.txt não deve conter linhas em branco (brancas).
O asterisco (*) só é aceito no campo Agente do usuário.
Não pode ser usado como um caractere curinga (ou como um operador de truncamento) como no exemplo: Disallow: / entravaux / *.
Não há campo correspondente à permissão, do tipo Permitir:.
Finalmente, o campo de descrição (User-agent, Disallow) pode ser inserido em letras minúsculas ou maiúsculas.
As linhas que começam com um sinal "#", ou seja, qualquer coisa à direita deste sinal em uma linha, são consideradas um comentário.
Aqui estão alguns comandos clássicos e importantes do arquivo robots.txt:
Disallow: / Usado para excluir todas as páginas do servidor (nenhuma aspiração possível).
Disallow: Permite não excluir nenhuma página do servidor (sem restrição).
Um arquivo robots.txt vazio ou inexistente terá o mesmo efeito.
User-Agent: googlebot Usado para identificar um robô específico (aqui, o do google).
User-agent: googlebot
Disallow:
User-agent: *
Disallow: / Permite ao google spider sugar tudo, mas nega outros bots.
Mapa do site e robots.txt
Para auxiliar Google, Yahoo ou outros, e principalmente os engines que não fornecem interface tendo a possibilidade de indicar-lhes o arquivo de mapa do site de um site, pode-se adicionar a indicação no arquivo, utilizando a seguinte sintaxe:
Mapa do site: https://monsite.info/
(mais se vários arquivos de mapa de site ...)
para Google ou Bing
ou também:
Mapa do site: https://monsite.info/
mais específico para o Yahoo ...
Gerador de arquivo Robots.txt
Se você deseja criar um arquivo robots.txt de forma fácil, simples e ter certeza de que ele é válido, você também pode usar um gerador de robots.txt, como este por exemplo: gerador de arquivo robots.txt
Todas as explicações online
O site de referência
ou para mais definições 'básicas':
em francês na wikipedia
Observe também esta indicação muito recente encontrada na Internet:
Um usuário acaba de descobrir que o Google levou em consideração uma diretiva chamada "noindex" quando foi inserida no arquivo "robots.txt" de um site, como:
User-agent: Googlebot
Disallow: / perso /
Disallow: / entravaux /
Noindex: / clientes /
Enquanto a diretiva "Disallow" diz aos robôs para ignorarem o conteúdo de um diretório (sem indexação, sem rastreamento de link), "Noindex" seria reduzido para não indexar páginas, mas identificar os links que elas contêm. Um equivalente da metatag "Robôs" que conteria a informação "Noindex, Seguir" de certa forma. O Google teria indicado que esta menção estaria em teste atualmente, que é suportada apenas pelo único Google mas que nada diz que será aprovada in fine. Para ser usado e testado com cuidado, portanto ...!
nota: a melhor solução para este ficheiro de "clientes", restando bloqueá-lo através de um '.htaccess' que será válido para todos os motores ...;)